Urban sensor networks often have to deal with a particular challenge: how to get data from the device to a server. Depending on your budget and data needs, there are various options, from low-power wide area networks (LP-WANs such as LoRaWAN) to cellular modems.
Rain gauge, river, temperature and other sensors might typically send a tiny amount of data periodically, a single measurement every 10 minutes for example.
Low-power networks are ideal, but require some form of network to get the data from the device to a gateway, and ultimately on to a server. There are lots of efforts to create community networks, such as The Things Network, but they’re by no means universal.
Building a sensor with a cheap (think $2) ESP device1 is relatively easy, and typically come with wi-fi. LoRA hats and antennae add to the cost – admittedly they seem to have come down since I last looked a few years ago – this one’s about £14.
Given that wi-fi is pretty ubiquitous in urban areas, couldn’t we leverage this to send data? Enter DNS Tunnelling. I first read about this years ago when a proof of concept was developed to tunnel regular traffic over DNS – a potential way to gain Internet access without signing over your personal details to public wi-fi networks.
DNS Tunnelling takes advantage of the fact that – although public wi-fi networks typically intercept web browsing (to block you until you agree to terms), they can’t reliably block DNS without breaking a whole bunch of browser functionality in the process.
So, theoretically, a device could connect to a public wi-fi network, send its data via DNS, receive instructions (in the DNS reply, if needed) and disconnect again, all without having to navigate login screens and minimising traffic.
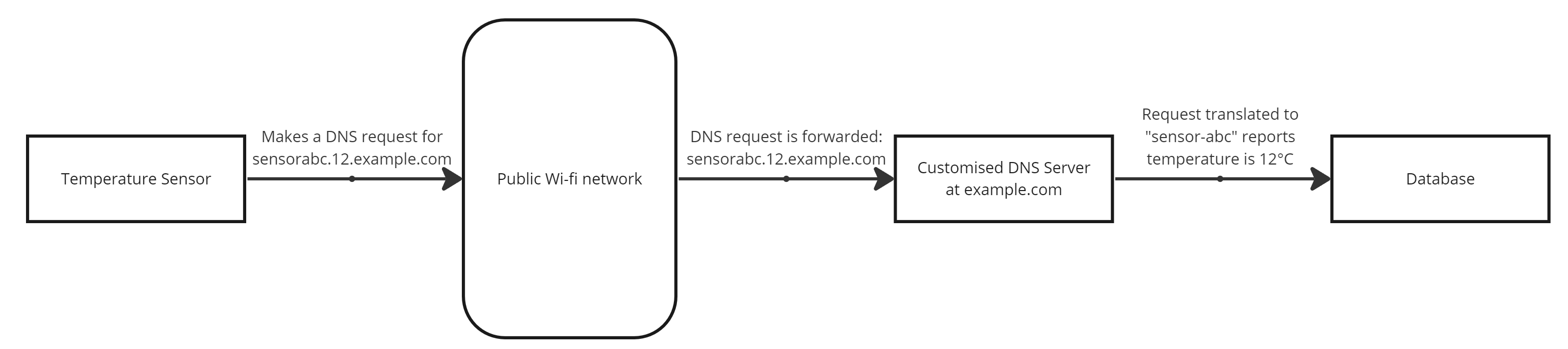
I started to look into this during my time working on IoT devices, as it would have significant cost benefits versus rolling out low-power networks or subscription cellular services.
A network of this type requires two key items: a device that can find and connect to public wi-fi networks (relatively easy with Arduino, Raspberry Pi, etc.), and a DNS server on the Internet capable of translating requests into specific packets of data (various options are ripe for modification).
However, there are significant implications around using public networks in this way, which I’d never explored fully before I left this particular project. Although I do wonder whether network operators would cause a fuss over a few kilobytes of data, in the context of urban city-wide public wi-fi installations. So, while my closed tests appeared to suggest it would work quite well, a rollout of any kind would need to be properly scrutinised and sanctioned by the operators.
Nonetheless, communications remains a major factor – particularly around low-budget sensor networks. Although it seems costs are falling, coverage is improving and – if you are building out a low-power network – consider the added benefits of joining one of the various networks to pool resources.
- Yes, I know a $2 device isn’t going to have the best antenna, although still potentially good enough for this to work in many locations. ↩︎


